如何实现基于Jupyter Notebook的数据服务
2021-05-24
Jupyter与文学式编程
Jupyter Notebook深受数据科学家/工程师们的喜爱,它允许使用者一边写数据处理代码,一边撰写相关的说明文字和图表以解释结果,向其他人传递自己的思想,同时也让文学式编程(Literate programming)重新回到了人们的视野。
文学式编程是由Donald Knuth提出的编程方法。传统的结构化编程,人们需要按计算机的逻辑顺序来编写代码;与此相反,文学式编程则是让人们按照自己的思维逻辑来开发程序。简单来说,文学式编程的读者不是机器,而是人。 我们从写出让机器读懂的代码,过渡到向人们解说自己的编程逻辑以及如何让机器实现我们的想法,其中除了代码,更多的是叙述性的文字、图表等内容。这正是数据分析人员所需要的编码风格——不仅要当好程序员,还得当好作家。写代码的目不只是为了机器的执行,还需要让其他人理解我们是如何解决问题,以及透过编程技术,呈现对数据的洞察力。编程就好比显微镜,把数据背后的细节和机理透过显微镜映射到人的观念和思维中,帮助我们解决复杂问题以及辅助决策。
Jupyter Notebook 虽然给使用者提供了方便进行文学式编程的环境,便于以 Notebook 为载体向其他人讲解自己的数据分析流程以及建模过程,但要将自己的模型部署为一个方便可用的服务(比如一个数据微服务),则显得并不是那么直接。Jupyter Kernel Gateway则给我们提供了一个不错的选择。
Jupyter Kernel Gateway的功能
要了解Jupyter Kernel Gateway(以下简称KG)实现了什么功能,我们需要先简单了解Jupyter的技术架构。
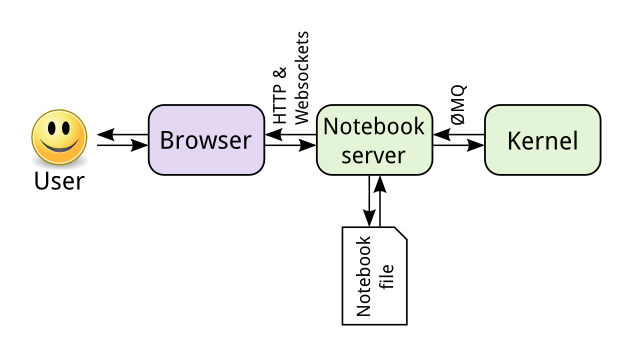
如上图所示,用户要在Jupyter系统中运行一个Notebook,需要通过浏览器与一个Notebook Server进行交互,通过这个Server对Notebook进行编辑,若要执行Notebook中的代码,则Notebook Server将要执行的代码发送给后端的一个Kernel执行引擎运行,再将结果返回并保存到Notebook中。全过程中,Notebook作为 Jupyter的前端除了接收使用者的操作指令,还保存了代码和相应的输出以及Markdown笔记等,在使用者要保存文件时,Notebook Server 将Notebook的内容保存到一个ipynb文件中。而Kernel只是一个遵循标准的执行引擎,理论上它并不必须与Notebook Server在一个服务器上(虽然一般情况下,它们是运行在一台机器上的),在有些情况下,比如为了提高代码的执行效率,我们希望将Kernel部署到性能更好的服务器或是集群上时,KG就为Notebook与一个远程Kernel进行连接提供了支持。此时,Jupyter的技术架构则会如下图所示。
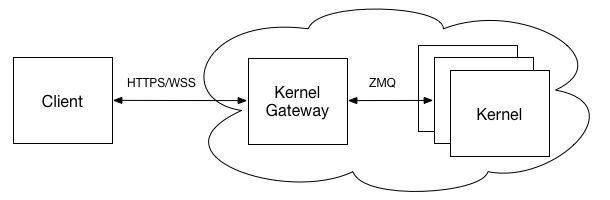
看到这里,其实可以发现,若想将自己写好的Notebook作为服务供其他人使用,只需要允许其他人访问一个Kernel并调用自己的Notebook的适当部分即可。
通过Jupyter Kernel Gateway远程运行自己的Notebook
KG的安装等操作这里就不赘述了,可以通过pip或conda方便地安装,具体可以参考手册。
这里我通过一个例子介绍它地使用方法。
我现在写了一个数据处理函数,它接收一个矩阵的行数(rows)作为参数,经过几步计算后返回一个数值。
import numpy as np
def data_process(rows):
"""Sample function."""
assert isinstance(rows, int) and rows>0
return np.matmul(np.random.rand(rows, 5), np.random.rand(5, 3)).sum()
我希望其他用户可以利用 RESTful API 来调用这个函数。此时,我可以在 Notebook 中的一个新的cell中,建立调用接口,如下:
# GET /get_results
req = json.loads(REQUEST)
args = req['args']
if 'rows' not in args:
print(json.dumps({'results': None}))
else:
try:
rows = args['rows']
res = data_process(rows)
except:
res = None
print(json.dumps({'results': res}))
之后在中断运行jupyter gateway命令:
jupyter kernelgateway --KernelGatewayApp.api='kernel_gateway.notebook_http' --KernelGatewayApp.seed_uri='/Users/user/sample.ipynb' --port=7001
用户只需要使用
http://127.0.0.1:7001/get_results?rows=10
这样的API即可调用我的函数。通过API传入的参数rows会被保存在名为 REQUEST 的 json 结构体里,具体使用方法可详细参考文档。
参考信息
- https://towardsdatascience.com/expose-endpoints-using-jupyter-kernel-gateway-e55951b0f5ad