如何用Python读取PDF文档内容
2020-07-30
PDFMiner
在Python生态下,一般会用 PDFMiner(现在的全名叫做pdfminer.six)来读取PDF文件的内容,很多其它package也都会封装pdfminer作为软件的底层,提供更多方便的上层接口。尽管这个包应用很广泛,但对整个package深入介绍的文档却比较少,自己搜到一些资料,整理如下。
有人说“PDF is evil.”因为PDF文档里的内容并不像word或html里的文档内容,有严格的行、段落等标记。你可以把PDF文件里的内容看成是一个个字符,以及记录每个字符该在哪个位置的集合(有点类似于图片,比如两个相连的字,你觉得他们是一个连续的词,而pdf实际只记录了两个单独的字,以及他们各自的坐标)。这就是为什么从pdf文件里读取文本,经常会出现杂乱的结构的原因。
PDFMiner的功能则可以粗略归结为两点:
-
从pdf文件里读出里面的字符以及每个字符的位置;
-
根据一定的规则,将这些字符连接为正常的文本。
PDFMiner是如何工作的
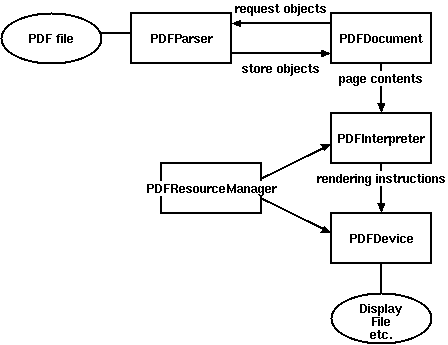
为了实现以上功能,PDFMiner中实现了一系列类:PDFParser和PDFDocument(这两个类紧密相连,PDFParser用来从pdf文件里读取数据,PDFDocument用来存储这些数据),PDFPageInterpreter(用来处理每页的内容),PDFDevice(用来将pdf中的信息转化成你需要的特定格式),以及PDFResourceManager(用于保存文件中一些共享的资源,如字体和图片等)。
下图描绘了这些类的功能关系。
一段代码示例:
import pdfminer
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage, PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
fp = open('sample.pdf', 'rb')
# Create a PDF parser object associated with the file object
parser = PDFParser(fp)
# Create a PDF document object that stores the document structure.
# Password for initialization as 2nd parameter
document = PDFDocument(parser)
# Check if the document allows text extraction. If not, abort.
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
# Create a PDF resource manager object that stores shared resources.
rsrcmgr = PDFResourceManager()
# Create a PDF device object.
#device = PDFDevice(rsrcmgr)
# BEGIN LAYOUT ANALYSIS.
# Set parameters for analysis.
laparams = LAParams(
char_margin=10.0,
line_margin=0.2,
boxes_flow=0.2,
all_texts=False,
)
# Create a PDF page aggregator object.
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# Create a PDF interpreter object.
interpreter = PDFPageInterpreter(rsrcmgr, device)
# loop over all pages in the document
for page in PDFPage.create_pages(document):
# read the page into a layout object
interpreter.process_page(page)
layout = device.get_result()
for obj in layout._objs:
if isinstance(obj, pdfminer.layout.LTTextBoxHorizontal):
print(obj.get_text())
上面这段代码中涉及PDFPageAggregator的部分,下面会介绍。
由于pdf文件里的文本往往缺少对于行、段落等结构的描述,所以PDFMiner要根据一些规则,自己来完成这个“组合”的工作,这就依赖于PDFPageAggregator和LAParams两个类,通过他们的处理,每页的内容(文本结构-layout)会以一个树形结构保存下来。
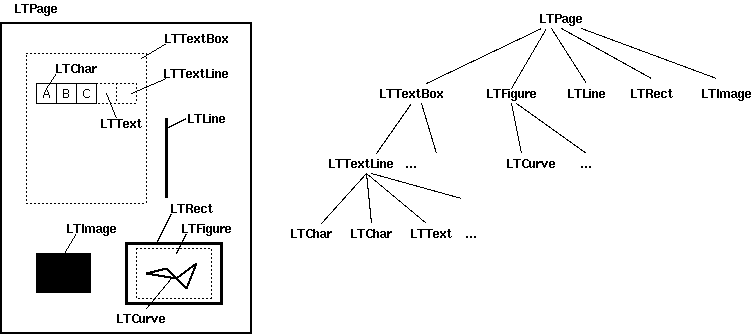
这个树形结构以“页”为单位,最上层是LTPage,它下面可以包含LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine等不同类。
-
LTTextBox表示一组包含在一个矩形区域的文本,需要注意的是,这组文本只是根据“空间关系”聚合在一起的,并不表示它们之间存在语义的逻辑关系(后面会介绍如何聚合文本)。LTTextBox下会包含一个LTTextLine的list。 -
LTTextLine表示一个文本行,它是由一系列LTChar组成的,LTChar表示一个字符。 -
LTFigure表示pdf文件中的一个内嵌区域,它里面可以包含线条、文本或图片,是一个嵌套的结构。 -
LTImage表示插入的图片。
更多类别的介绍可以查询官方文档。
通过以上类,我们可以从pdf文件中读取不同的文本和图片等内容。
PDFMiner是如何对文本进行组合的
PDFMiner是基于字符的位置进行文本组合的,大致按照如下的顺序:首先根据两个字符的空间位置来判断它们是否应该连接成一个文本行;在此基础上,再根据行与行之间的间隔,来判断他们是否可以组成一个文本段;最后,再根据每个文本段的空间位置,基于行优先或列优先(或介于两者之间的一种规则)输出文本,实现将pdf文件的内容转成文本内容。这部分内容在官方文档中介绍得比较清楚。
在实际使用中,由于PDF文档自身的排版结构多种多样,所以往往需要使用者根据文档结构设置文本聚合的方法,具体可以设置LAParams的各个参数,并根据导出文本的坐标位置进行二次组合。具体可以参考pdfminer的官方教程。
注:本文章内的部分内容和图片来自于Programming with PDFMiner.